Neomezené seskupování ve výkazech
Dialog pro seřazení a seskupení položek ve výkazu tradičně nabízí možnost seskupit položky se shodnými hodnotami. Boh užel jsme omezeni pouze na čtyři parametry, podle kterých seskupujeme, což obvykle stačí. V článku si ukážeme, jak postupovat v případě, kdy je potřeba tento limit prolomit.
Takovou situaci je potřeba řešit při zpracování výpisu prvků, kdy je potřeba položky obsahující shodné hodnoty jednotlivých parametrů třídit a seskupit. Často se jedná o parametry instanční, kde může mít každý element libovolnou hodnotu. S parametry typu takový problém nebývá, tady obvykle stačí seskupovat přes parametr Název typu, protože v rámci jednoho typu nemůže dojít k rozdílnosti hodnot.
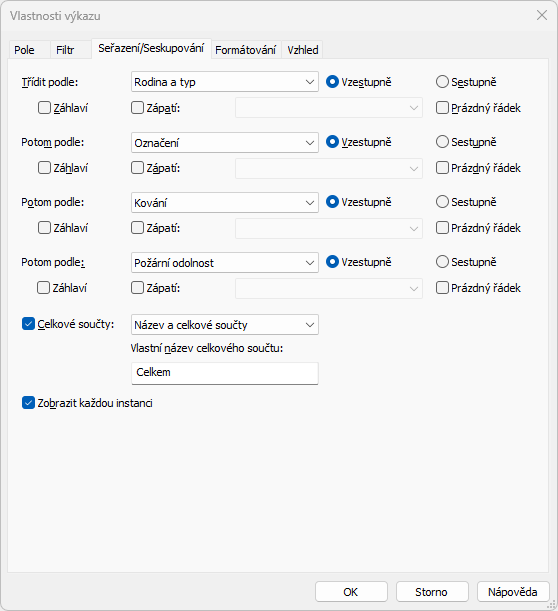
Pokud element (typicky například dveře) obsahuje velké množství instančních parametrů a my následně máme potřebu do jednoho řádku seskupit takové položky, které jsou pro vybrané parametry shodné, jsme omezeni na 4 parametry. Pokud je jich víc, máme trochu problém. S uvedeným omezením si při seskupování nevystačíme a v některých buňkách výkazu se zobrazí "<více rozdílných hodnot>".
Seskupení parametrů
Pro naše řešení, asi tak první ,co by nás mohlo napadnout, by bylo využití nástroje Sloučit parametry, který nájdeme v dialogovém okně výkazu. Hodnotu vzniklého parametru tak lze snadno poskládat z vícero jiných existujících parametrů. Tuto funkci používám nejen ve výkazech, ale i v popiskách - typicky, pokud třeba skládám kódové označení místnosti nebo kódu prvku z více samostatných parametrů.
Tento parametr by nyní bylo hezké použít pro seskupování a měli bychom vystaráno. Bohužel to nejde. V nabídce parametrů pro třídění a seskupování nám sloučené parametry chybí, roletka zobrazuje pouze parametry projektu, systémové parametry Revitu a sdílené parametry rodin.
Vlastní seskupovací nástroj
Jak už to tak bývá, kde přirozené nástroje Revitu selhávají, tam situaci často vyřeší Dynamo nebo nějaký aplikační doplněk. I tato situace je tento případ.
Budeme postupovat následovně: Vytvoříme si nový ("třídící") parametr projektu pro danou kategorii výkazu a vytvoříme skript, který nejprve od každého elementu posbírá potřebná (většinou asi instanční) data, seskupí je do jednoho dlouhého řetězce a následně zapíše hodnotu do "třídícího" parametru.
Samotný Dynamo skriptík není žádné velké inženýrství. Je potřeba jej spustit nad aktivním pohledem s výkazem a předat mu pouze seznam zdrojových parametrů a cílový parametr, kam skript sloučený řetězec zapíše. Skript vypadá nějak takto.
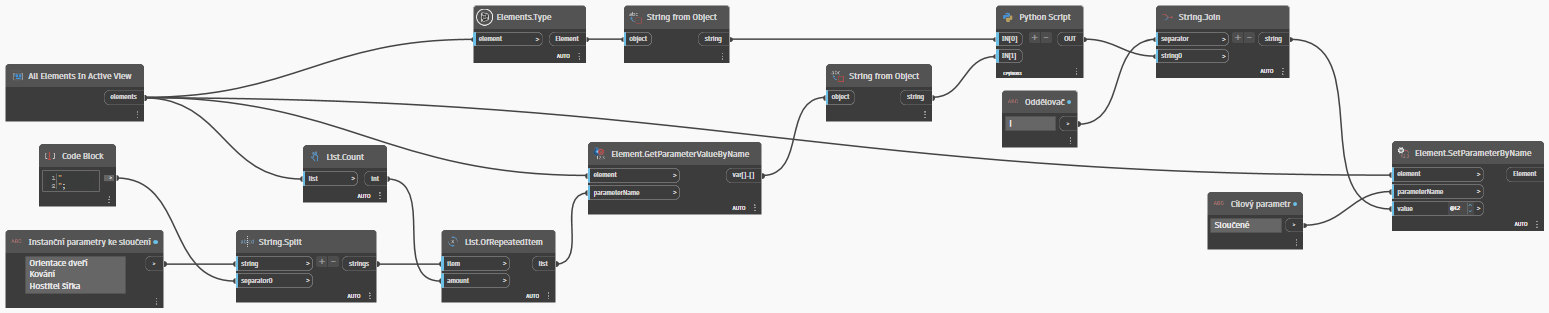
Zde je pak obsah Python skriptu:
seznam1 = IN[0]
seznam2 = IN[1]
# Výstupní seznam
seskupene = []
# Spojení řádků
for i in range(len(seznam1)):
row = [seznam1[i]] + seznam2[i]
seskupene.append(row)
# Výstup
OUT = seskupeneTento kód je potřeba vložit do Nodu Python Script.
Po sloučení a překopírování dat do třídícího parametru je potřeba nastavit třídění přes tento zpravidla už jediný parametr. Data by se měla seskupit tak, že v žádném ze sloupečků, jejichž data jsme použili pro sloučení, by teď nemělo být zobrazeno "<více rozdílných hodnot>". Nyní s daty můžeme provést požadovanou operaci - například je očíslovat, což je asi tak nejběžnější operace, kterou potřebuju udělat.
Takže tak :)